In this article we will explore geocoding using the Google Maps API and the placement, ggmap, and googleway packages in R. We will work with some raw data from Clarivate Analytics Web of Science database of scientific literature. Many universities have access to Web of Science and it is a very important tool in fields such as bibliometrics/scientometrics. This article is part of work in progress for the WIPO Patent Analytics Handbook. The aim of the article is to explore geocoding issues involving the scientific literature in depth and move closer to a solution using R.
Geocoding is the process of taking a name and address and looking up the geographic coordinates expressed in latitude and longitude. This is normally done using a web service. There are plenty of example walkthroughs on how to do this. However, many of them start with data that is already clean. We will be working with data that is really rather messy.
What we are attempting to do is to obtain the addresses and coordinates from the author affiliations field in Web of Science records. Our dataset is from a set of queries for scientific literature for South East Asia (ASEAN) countries that involve marine organisms. We have a table with 5,206 author affiliation details containing the names of organisations, the city and the country. This data is not clean and contains multiple minor variations of the same organisation name. The data also contains variations in geographic locations such as references to a district within a city rather than the name of the city itself. To follow the walk through you can download the data from Github here. It simply contains the author affiliation name and a count of the number of records.
One of the issues with Web of Science data is that the names of organisations are abbreviated/stemmed (so that University becomes Univ, Institute becomes Inst and so on and so on). Until recently this made geocoding a significant headache. However, as we will see below the Google Maps API now seems to do a very good job of handling these issues but considerable care is needed when interpreting the results.
In this article we will go step by step through the process of geocoding and deal with the issues we encounter along the way. At the end of the article we will pull the code together to identify a more efficient way to deal with geocoding Web of Science and similar data.
By the end of this article you will be familiar with what geocoding is and how to carry out geocoding using the placement, ggmap and googleway packages in R with RStudio. You will also be familiar with the Google Maps API and be able to identify and retrieve missing data using packages from the tidyverse. We will take what we learned and combine it into more efficient code for solving the problem and finish off with a quick map of the results.
Getting Started
If you are new to R and RStudio then first we need to get set up. To install R for your operating system choose the appropriate option here and install R. Then download the free RStudio desktop for your system here. We will be using a suite of packages called the tidyverse that make it easy to work with data. When you have installed and opened RStudio run these lines in your console to install the packages that we will be using.
install.packages("tidyverse")
install.packages("placement")
install.packages("devtools")
install.packages("usethis")
install.packages("googleway")For ggmap we will load the latest version 2.7 that includes register_google() for authentication and install it from github as follows.
devtools::install_github("dkahle/ggmap")Next load the libraries.
library(tidyverse)
library(ggmap)
library(placement)
library(usethis)
library(googleway)You will now see a bunch of messages as the packages are loaded. You should now be good to go.
If you would like to learn more about R then try the excellent DataCamp online courses or read Garrett Grolemund and Hadley Wickham’s R for Data Science. Learning to do things in R will make a huge difference to your ability to work with patent and other data and to enjoy the support of the R community in addressing new challenges. There is never a better time to start learning to do things in R than right now.
The placement, ggmap and recent googleway packages all provide functions for geocoding with the Google Maps API. The placement package by Derek Darves was created in 2016 and provides straightforward access to the Google Maps API and additional tools for address cleaning, calculating distances and driving times. As Derek explains here. I found it remarkably easy to use and it does not require any complicated code. The function we will be using is geocode_url() and geocode_pull(). That is basically it.
While placement mainly focuses on geocoding, ggmap is a bigger package for mapping in R that includes geocoding. The package is a complement to ggplot2 and a Data Camp course by Charlotte Wickham Working with Geospatial Data in R will get you started in no time with ggmap and other mapping packages. As we will see below, I ran in to some tricky issues when trying to geocode with ggmap and you may also want to give googleway a try.
We will mainly use the placement package because I like the simplicity of the package, but which you use will depend on your purpose and you will probably want to experiment with the wider functionality of ggmap or the more recent googleway.
Getting set up with the Google Maps API
To use the Google Maps API you will need to:
- Sign in to a Google account
- Get a free API key from here.
This involves pressing the Get a Key button and creating a project (app) that you will query by following these steps.
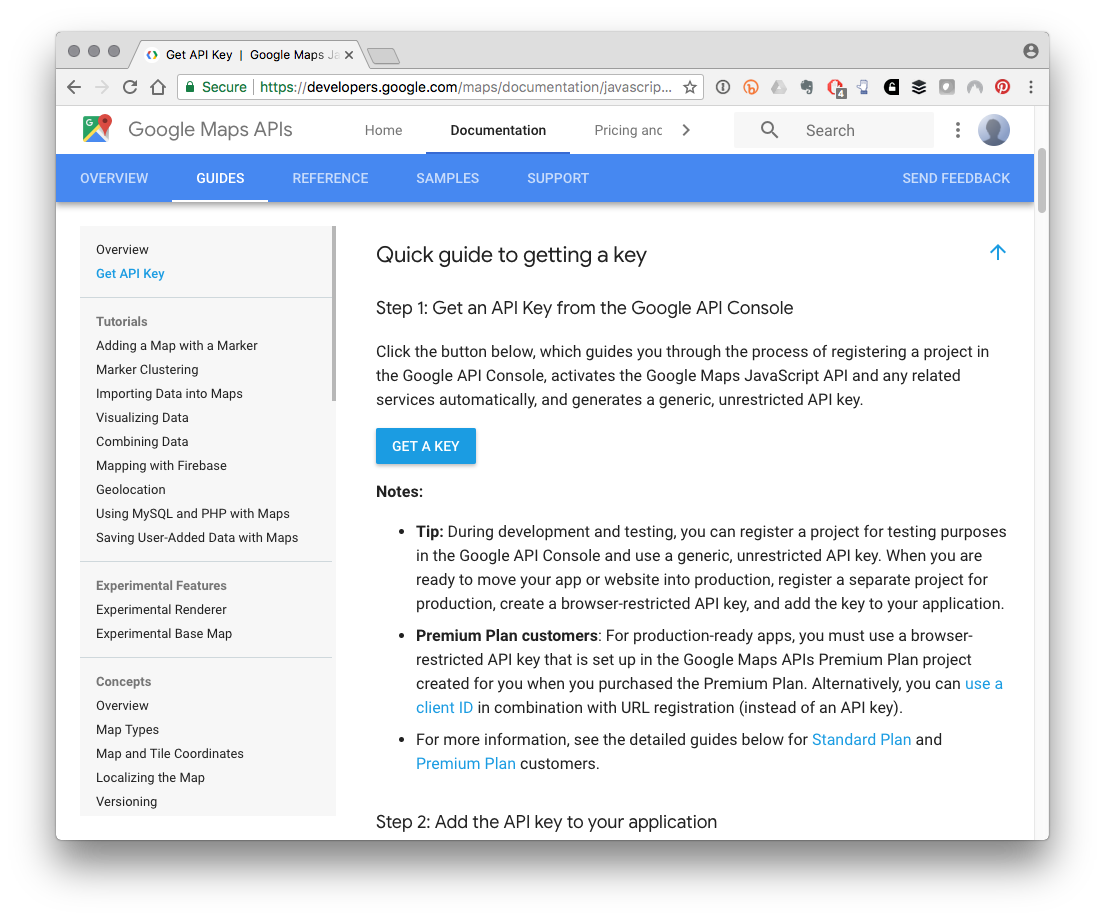
Create a new project and wait a short while while Google spins it up.
You will then see your API key. Note that you will see a link to restrict access to your API. It is a good idea to follow this and use your IP address to limit access to your IP address under Application restrictions. This will prevent other people from using the account if they discover the API key. We will not go down that route right now.
Take a copy of your API key (say into a text file in R Studio). What you do next is up to you.
- Save the text file somewhere sensible and copy it into the functions below when needed.
With
usethiseither:usethis::edit_r_environ()to open your local environment file and enter something like GOOGLE_MAPS_KEY=“yourkey” and then restart R. You will be able to access the key usingSys.getenv("GOOGLE_MAPS_KEY").usethis::edit_r_profile()and enter google_maps_key=“your key”, inside the existing options() chunk, save and restart R. Call the key withgetOption("google_maps_key")
For discussion on the above try reading the R startup section of Efficient R Programming or follow the very useful ROpenSci instructions. usethis makes life much easier because it knows where the files are!
We will go with the usethis::edit_r_environ() environment option, so let’s store the key in our working environment for the moment using the imaginatively named key.
key <- Sys.getenv("GOOGLE_MAPS_KEY")Using the API
Note that API queries are limited to a free 2500 per day. It costs 50 cents per 1000 queries after that. As this would not break the bank we simply signed up for a billing account to run the full list. As we will see below signing up for an API key is a good idea to avoid problems with the return resulting from pressure on the free service. When you sign up for the API key you still get the 2500 results but make sure you put your API key somewhere safe and do not make it public.
Below we will briefly show how to use the placement, ggmap and newer googleway packages to retrieve geocode data. Unfortunately the return from the Google API with placement also includes a column called input_url. I say unfortunate because the input_url includes your private API key! So, if you are planning to make any of this data public you should exclude the input_url column.
The Source Data
Next let’s take a quick look at the source data. When we send the addresses to the Google Maps API with placement it will return the original search terms in a column called locations. To make our life easier we renamed the original column in our source dataset. Note that the records field refers to the number of publications associated with an address and will allow us to size dots on any map we produce with the results. We can import the data directly from Github.
affiliation_records <- read_csv("https://github.com/wipo-analytics/data-handbook/raw/master/affiliation_records.csv")head(affiliation_records)## # A tibble: 6 x 3
## records locations id
## <int> <chr> <int>
## 1 1 AAHL, Vic, Australia 1
## 2 1 AAHRI, Bangkok, Thailand 2
## 3 1 Aarhus Univ Biosci, Roskilde, Denmark 3
## 4 1 Aarhus Univ Hosp, Aarhus, Denmark 4
## 5 13 Aarhus Univ, Aarhus C, Denmark 5
## 6 3 Aarhus Univ, Aarhus, Denmark 6Lookup the Records
In this section we will look up some of the records with each of the three packages to show how easy it is. Purely from personal preference we will use placement for the rest of the work.
Using placement
The placement package can do more than we will attempt here. For example, you can attempt address cleaning or calculating driving distances with placement. For our purposes the main event is the geocode_url() function, We pass the data in the locations column to the function along with the authentication route and the private key. The clean = TRUE argument applies the address_cleaner function before encoding the URL to send to the API. The default is set to TRUE and you may want to experiment with setting this value to FALSE. We also add the date of search as it is always useful to know when we carried out the search and we set verbose to TRUE to receive more information. Note that other arguments such as dryrun can be useful for debugging problem addresses.
Note that the key can be entered directly into geocode_url() as privkey = Sys.getenv("GOOGLE_MAPS_KEY"). However, I found that this sometimes returned an error message on long runs. For that reason we might copy it into our local environment (and be careful not to expose it).
key <- Sys.getenv("GOOGLE_MAPS_KEY")library(placement)
coordaffil <-
geocode_url(affiliation_records$locations, auth = "standard_api", privkey = key, clean = TRUE, add_date = 'today', verbose = TRUE)Using ggmap
We can perform the same lookup using ggmap and the geocode() function. Note that the function defaults to the free allocation of 2500 queries. There are options to return “latlon” and “latlona”" or “more” or “all”. In the case of “all” this returns a list with entries of differing lengths that you will need to wrangle. In general use latlon, latlona or more as this will return a data frame. Here we will just test 100 records. geocode() does not return the input URL with our private key (which is good).
library(ggmap)
coord_ggmap <-
geocode(location = affiliation_records$locations[1:100],
output = "more", source = "google",
messaging = FALSE)When using ggmap I encountered a significant number of OVER_QUERY_LIMIT entries in the return. Why is something of a mystery although as discussed here this may because we are sharing the call to the free service with others. It is therefore better to get a key if you are going to be using this service. To authenticate using ggmap (2.7 only) create a key based on the key in your environment file. Pass it to register_google() and then you are ready to make the call.
key <- Sys.getenv("GOOGLE_MAPS_KEY")
register_google(key = key)It will now work smoothly.
library(ggmap)
ggmap1 <-
geocode(location = affiliation_records$locations[201:300],
output = "more", source = "google",
messaging = FALSE)This overcame the limitation and returned a data.frame with 100 entries.
ggmap1 %>%
select(1:4) %>%
head()## lon lat type loctype
## 1 -93.631913 42.03078 locality approximate
## 2 3.707011 51.05376 establishment rooftop
## 3 -1.386919 50.90853 establishment geometric_center
## 4 142.384141 43.72986 establishment rooftop
## 5 142.384141 43.72986 establishment rooftop
## 6 127.680932 26.21240 administrative_area_level_1 approximateUsing Googleway
An alternative to placement or ggmap is also available using the googleway package. googleway includes access to the Google APIs for directions, distance, elevation, timezones, places, geocoding and reverse geocoding and so has a wider set of uses. However, googleway is expecting an address field of length 1 (meaning it takes one address at a time) whereas placement and ggmap are vectorised. The return from googleway returns a list object containing a data frame with the results and the status of the return. Here is one quick example.
library(googleway)
googleway <-
google_geocode(address = "Aarhus Univ Biosci, Roskilde, Denmark", key = Sys.getenv("GOOGLE_MAPS_KEY"), simplify = TRUE)For long lists we would therefore need to use an approach such as lapply() or purrr::map() to make the call as a set and then look at ways to bind the results together.
googleway2 <-
purrr::map(affiliation_records$locations[1:2], google_geocode, key = Sys.getenv("GOOGLE_MAPS_KEY"), simplify = TRUE)As this makes clear, you have at least three choices for geocoding and which you prefer will depend on your needs. I found ggmap rather awkward because the existing CRAN version (2.6) does not provide the register_google() function in the long standing 2.7 development version. While this is a bit awkward ggmap provides some very powerful features that you will want to use. On the other hand googleway would involve some more work to vectorise over the list as we started exploring above. placement on the other hand is fine with the only disadvantage being the return of the API key in the input URL that we have to remember.
Reviewing Initial Results
When we originally started working with the Google API in 2017 the API returned 3,937 results from the 5,206 names. This then required a lot of additional work to retrieve the remaining numbers by cleaning up abbreviations and country names. However, the Google Maps API seems to have improved rather radically in the meantime.
Let’s take a look at the issues that can arise with the return from the Google Maps API. For the moment we will focus on the completeness of the data revealed in status and error messages.
coordaffil %>%
select(location_type, status, error_message) %>%
head()## location_type status error_message
## 1 ROOFTOP OK
## 2 GEOMETRIC_CENTER OK
## 3 ROOFTOP OK
## 4 GEOMETRIC_CENTER OK
## 5 ROOFTOP OK
## 6 ROOFTOP OKThe return from placement is a data.frame that is exactly the same length as our input. What we need to watch out for are the entries in the status column and the error message column. Here we need to be cautious because most of the time the API returns either “OK” or “ZERO_RESULTS”. However, there are additional status codes listed here and they are also listed in the documentation for geocode_url(). They are:
- “OK”
- “ZERO_RESULTS”
- “OVER_QUERY_LIMIT”
- “REQUEST_DENIED”
- “INVALID_REQUEST”
- “UNKNOWN_ERROR”
- “CONNECTION_ERROR” (added)
When running a long set of addresses the CONNECTION_ERROR can creep into the data, so be aware of this.
We can now join our data sets together. We will use left_join() for convenience and specify the column to join on as the shared locations column.
results <-
dplyr::left_join(affiliation_records, coordaffil, by = "locations")We can identify the results found so far by filtering on the status field which will show “OK” where there is a return and “ZERO_RESULTS” where the geocoding did not work:
results %>%
filter(., status == "OK")## # A tibble: 5,187 x 10
## records locations id lat lng location_type formatted_address
## <int> <chr> <int> <dbl> <dbl> <chr> <chr>
## 1 1 AAHL, Vic… 1 -38.2 144. ROOFTOP 5 Portarlington R…
## 2 1 AAHRI, Ba… 2 13.8 101. GEOMETRIC_CE… 50, กรมประมง, ถนน…
## 3 1 Aarhus Un… 3 56.2 10.2 ROOFTOP Nordre Ringgade 1…
## 4 1 Aarhus Un… 4 56.2 10.2 GEOMETRIC_CE… Nørrebrogade, 800…
## 5 13 Aarhus Un… 5 56.2 10.2 ROOFTOP Nordre Ringgade 1…
## 6 3 Aarhus Un… 6 56.2 10.2 ROOFTOP Nordre Ringgade 1…
## 7 1 Abasyn Un… 7 34.0 71.6 GEOMETRIC_CE… Ring Road, Charsa…
## 8 1 Abdul Wal… 8 34.2 72.0 GEOMETRIC_CE… Nowshera Mardan R…
## 9 1 Abertay U… 9 56.5 -2.97 GEOMETRIC_CE… Bell St, Dundee D…
## 10 1 Aberystwy… 10 52.4 -4.07 GEOMETRIC_CE… Penglais Campus, …
## # ... with 5,177 more rows, and 3 more variables: status <chr>,
## # error_message <chr>, geocode_dt <date>For the results that were not found it is safest not to simply filter for ZERO RESULTS but instead to filter for anything that is not OK using !=. This can save on endless hours of confusion where you have multiple messages in the status column.
lookup <- results %>%
filter(., status != "OK")
nrow(lookup)## [1] 19So, we have 19 records with no results. That is pretty good from just over 5000 results.
lookup %>%
select(-id)## # A tibble: 19 x 9
## records locations lat lng location_type formatted_addre… status
## <int> <chr> <dbl> <dbl> <chr> <chr> <chr>
## 1 2 Aomori Prefe… NA NA <NA> <NA> ZERO_…
## 2 1 FOOD CROPS R… NA NA <NA> <NA> ZERO_…
## 3 2 Hunan Agr Un… NA NA <NA> <NA> ZERO_…
## 4 1 Hunan Fisher… NA NA <NA> <NA> ZERO_…
## 5 1 Hunan Univ C… NA NA <NA> <NA> ZERO_…
## 6 2 Indonesian I… NA NA <NA> <NA> ZERO_…
## 7 1 Inst Oceanog… NA NA <NA> <NA> ZERO_…
## 8 1 Inst Oceanog… NA NA <NA> <NA> ZERO_…
## 9 6 Inst Oceanog… NA NA <NA> <NA> ZERO_…
## 10 2 ISME, Okinaw… NA NA <NA> <NA> ZERO_…
## 11 1 Kitasato Uni… NA NA <NA> <NA> ZERO_…
## 12 1 Main Off Edu… NA NA <NA> <NA> ZERO_…
## 13 1 Nha Trang In… NA NA <NA> <NA> ZERO_…
## 14 1 Okinawa Pref… NA NA <NA> <NA> ZERO_…
## 15 1 Ryukoku Univ… NA NA <NA> <NA> ZERO_…
## 16 1 UNIV WESTMIN… NA NA <NA> <NA> ZERO_…
## 17 6 Vietnam Acad… NA NA <NA> <NA> ZERO_…
## 18 1 VNIO, Nha Tr… NA NA <NA> <NA> ZERO_…
## 19 1 Xi Consultan… NA NA <NA> <NA> ZERO_…
## # ... with 2 more variables: error_message <chr>, geocode_dt <date>When dealing with thousands of records it is often a good idea to add a cut off threshold. For example we can see above that with two exceptions the entries are all for 1 or 2 records. As these will be barely visible on a map you may want to set a cut off point to focus in on the more important records.
However, the lookup table highlights an issue that the Google Maps API previously struggled to deal with: abbreviations. When working with scientific literature abbreviations in author affiliations along with acronyms are common. So, lets look at how to deal with that.
Tackling Abbreviations
Here we have created a simple file containing some of the major Web of Science organisation abbreviations and their matches. It is probably not complete but is a good start. Next we added a column with word boundaries that we will use to find and replace the abbreviations. You can download the the file directly from Github.
wos_abbreviations <- read_csv("https://github.com/wipo-analytics/data-handbook/raw/master/wos_abbreviations.csv",
col_types = cols(abbreviation = col_character(),
text = col_character()))A simple word boundary regular expression was added to assist with matching.
wos_abbreviations$regex <-
paste0("\\b", wos_abbreviations$abbreviation, "\\b")## # A tibble: 6 x 3
## abbreviation text regex
## <chr> <chr> <chr>
## 1 Univ University "\\bUniv\\b"
## 2 Natl National "\\bNatl\\b"
## 3 Inst Institute "\\bInst\\b"
## 4 Sci Science "\\bSci\\b"
## 5 Ctr Centre "\\bCtr\\b"
## 6 Res Research "\\bRes\\b"To replace the abbreviations we will want to temporarily separate out the city and the country names in the locations column. This helps us to avoid transforming them by accident. We will bring the edited version back together later. Web of Science data uses a comma to separate out the entities and so we use that in a call to separate. We also keep the original column by specifying remove = FALSE as the default removes the input column.
lookup <-
lookup %>%
separate(., locations, c("organisation", "city", "country"), sep = ",", remove = FALSE)## # A tibble: 6 x 6
## records locations organisation city country id
## <int> <chr> <chr> <chr> <chr> <int>
## 1 2 Aomori Prefectural A… Aomori Prefectural… " Aom… " Japan" 161
## 2 1 FOOD CROPS RES INST,… FOOD CROPS RES INST " HAI… " VIETNA… 1215
## 3 2 Hunan Agr Univ, Huna… Hunan Agr Univ " Hun… " People… 1521
## 4 1 Hunan Fisheries Sci … Hunan Fisheries Sc… " Hun… " People… 1522
## 5 1 Hunan Univ Chinese M… Hunan Univ Chinese… " Hun… " People… 1523
## 6 2 Indonesian Inst Sci,… Indonesian Inst Sci " Amb… " Indone… 1597Next we want to iterate over the list of our organisation names and replace the abbreviations. There are a variety of ways to do that such as the qdap package function multigsub() or mgsub(). We like qdap a lot but installation of the package can be a bit awkward due to a dependency on rJava.1 Instead we are going to use a simple for loop (although a purrr solution would be an improvement).
replaceabbr <- function(pattern, replacement, var) {
replacement <- rep(replacement, length(pattern))
for (i in seq_along(pattern)) {
var <- gsub(pattern[i], replacement[i], var)
}
var
} One issue with cleaning names is capitalisation. For example, in our wos abbreviations file we have used Univ as the most common abbreviation for University. However, this will not match UNIV and so we will be better off regularising the text. A common convention is to convert everything to lower case using tolower() at the start of working with the data. Here we don’t want to do that. We will use the extremely useful stringr package to convert the organisation name to to title case in a new field that we will call organisation_edited. The reason that we are not editing our original column is that at some point we will want to join the table back on to our original dataset…so we don’t want to touch our original column. We will do this using mutate() from dplyr().
lookup <- lookup %>%
mutate(organisation_edited = str_to_title(.$organisation))
lookup %>% select(organisation_edited)## # A tibble: 19 x 1
## organisation_edited
## <chr>
## 1 Aomori Prefectural Agr & Forestry Res Ctr
## 2 Food Crops Res Inst
## 3 Hunan Agr Univ
## 4 Hunan Fisheries Sci Inst
## 5 Hunan Univ Chinese Med
## 6 Indonesian Inst Sci
## 7 Inst Oceanog Vast
## 8 Inst Oceanog
## 9 Inst Oceanog
## 10 Isme
## 11 Kitasato Univ
## 12 Main Off Educ & Teaching Area
## 13 Nha Trang Inst Oceanog
## 14 Okinawa Prefectural Fisheries & Ocean Res Ctr
## 15 Ryukoku Univ
## 16 Univ Westminster
## 17 Vietnam Acad Sci & Technol
## 18 Vnio
## 19 Xi ConsultancyNext, we transform the abbreviations using replaceabbr.
lookup$organisation_edited <-
replaceabbr(wos_abbreviations$regex, wos_abbreviations$text, lookup$organisation_edited)lookup %>%
select(organisation_edited)## # A tibble: 19 x 1
## organisation_edited
## <chr>
## 1 Aomori Prefectural Agriculture & Forestry Research Centre
## 2 Food Crops Research Institute
## 3 Hunan Agriculture University
## 4 Hunan Fisheries Science Institute
## 5 Hunan University Chinese Medical
## 6 Indonesian Institute Science
## 7 Institute Oceanography Vast
## 8 Institute Oceanography
## 9 Institute Oceanography
## 10 Isme
## 11 Kitasato University
## 12 Main Office Education & Teaching Area
## 13 Nha Trang Institute Oceanography
## 14 Okinawa Prefectural Fisheries & Ocean Research Centre
## 15 Ryukoku University
## 16 University Westminster
## 17 Vietnam Academy Science & Technology
## 18 Vnio
## 19 Xi ConsultancyThis is not perfect, for example we encounter issues with Agriculture and Agricultural and so on. We also encounter issues of capitalisation in the city and the country field that we are presently ignoring. However, it is good enough for the time being. Rather than focus on resolving a small number of remaining items the next step is to reunite the fields we separated into a field we will call locations edited using the tidyr unite function.
lookup <- lookup %>%
unite(., locations_edited, c(organisation_edited, city, country), sep = ",", remove = FALSE)
lookup %>%
select(organisation, city, country, locations_edited)## # A tibble: 19 x 4
## organisation city country locations_edited
## <chr> <chr> <chr> <chr>
## 1 Aomori Prefectural A… " Aomor… " Japan" Aomori Prefectural Agricultur…
## 2 FOOD CROPS RES INST " HAI H… " VIETNA… Food Crops Research Institute…
## 3 Hunan Agr Univ " Hunan" " People… Hunan Agriculture University,…
## 4 Hunan Fisheries Sci … " Hunan" " People… Hunan Fisheries Science Insti…
## 5 Hunan Univ Chinese M… " Hunan" " People… Hunan University Chinese Medi…
## 6 Indonesian Inst Sci " Ambon" " Indone… Indonesian Institute Science,…
## 7 Inst Oceanog VAST " Nha T… " Vietna… Institute Oceanography Vast, …
## 8 Inst Oceanog " Nha T… " Vietna… Institute Oceanography, Nha T…
## 9 Inst Oceanog " Nha T… " Vietna… Institute Oceanography, Nha T…
## 10 ISME " Okina… " Japan" Isme, Okinawa, Japan
## 11 Kitasato Univ " Aomor… " Japan" Kitasato University, Aomori, …
## 12 Main Off Educ & Teac… " Tehra… " Iran" Main Office Education & Teach…
## 13 Nha Trang Inst Ocean… " Khanh… " Vietna… Nha Trang Institute Oceanogra…
## 14 Okinawa Prefectural … " Okina… " Japan" Okinawa Prefectural Fisheries…
## 15 Ryukoku Univ " Okina… " Japan" Ryukoku University, Okinawa, …
## 16 UNIV WESTMINSTER " LONDO… " ENGLAN… University Westminster, LONDO…
## 17 Vietnam Acad Sci & T… " Nha T… " Vietna… Vietnam Academy Science & Tec…
## 18 VNIO " Nha T… " Vietna… Vnio, Nha Trang, Vietnam
## 19 Xi Consultancy " Delft" " Nether… Xi Consultancy, Delft, Nether…Note that rather than creating a separate character vector we made life easier by simply adding locations_edited to our lookup data.frame (because the vectors are of the same length) using unite().
Lookup edited names
We now send the cleaned up version off to the Google API.
library(placement)
coordlookup <- geocode_url(lookup$locations_edited, auth = "standard_api", privkey = key, clean = TRUE, add_date = 'today', verbose = TRUE)Let’s take a look.
coordlookup %>%
select(locations, status)## locations
## 1 Aomori Prefectural Agriculture & Forestry Research Centre, Aomori, Japan
## 2 Food Crops Research Institute, HAI HUNG, VIETNAM
## 3 Hunan Agriculture University, Hunan, Peoples R China
## 4 Hunan Fisheries Science Institute, Hunan, Peoples R China
## 5 Hunan University Chinese Medical, Hunan, Peoples R China
## 6 Indonesian Institute Science, Ambon, Indonesia
## 7 Institute Oceanography Vast, Nha Trang, Vietnam
## 8 Institute Oceanography, Nha Trang City, Vietnam
## 9 Institute Oceanography, Nha Trang, Vietnam
## 10 Isme, Okinawa, Japan
## 11 Kitasato University, Aomori, Japan
## 12 Main Office Education & Teaching Area, Tehran, Iran
## 13 Nha Trang Institute Oceanography, Khanh Hoa Prov, Vietnam
## 14 Okinawa Prefectural Fisheries & Ocean Research Centre, Okinawa, Japan
## 15 Ryukoku University, Okinawa, Japan
## 16 University Westminster, LONDON W1M 8JS, ENGLAND
## 17 Vietnam Academy Science & Technology, Nha Trang, Vietnam
## 18 Vnio, Nha Trang, Vietnam
## 19 Xi Consultancy, Delft, Netherlands
## status
## 1 ZERO_RESULTS
## 2 ZERO_RESULTS
## 3 OK
## 4 OK
## 5 OK
## 6 OK
## 7 ZERO_RESULTS
## 8 OK
## 9 OK
## 10 ZERO_RESULTS
## 11 ZERO_RESULTS
## 12 OK
## 13 ZERO_RESULTS
## 14 OK
## 15 OK
## 16 OK
## 17 OK
## 18 ZERO_RESULTS
## 19 ZERO_RESULTSSo, 8 of our revised names have failed to produce a return. In some cases this is a little surprising. For example the private Kitasato University would be expected to come up, but the reference to Aomori seems to have confused the mapper (as the University is listed as located in Minato). In the case of the Institute Oceanography Vast we can see that there is duplication (Vast refers to the Vietnam Academy of Science and Technology as the parent organisation of the institute) with the second and third entries being recognised. Other variants such as Nha Trang Institute Oceanography, Khanh Hoa Prov, Vietnam and the acronym Vnio, Nha Trang, Vietnam are also missed. How far you want to push with fixing addresses is up to you and will depend on your purposes. As mentioned above, to avoid a long tail of unresolved addresses for low frequency data you may want to use a cut off on the number of records.
Bringing the data together
To join the data back together we need to do some tidying up on the lookup and coordlookup table first. Recall that we sent edited names to Google and those were returned as locations. This means that they will not match with the names in our original table. We also created some additional columns. To create tables that will match the original table we need to tidy up by:
- selecting the original columns in lookup plus locations_edited (our join field)
- renaming locations to locations_edited in the lookup results (the join field)
- join the tables
- drop the locations-edited column
lookup <- lookup %>%
select(records, locations, locations_edited, id)
coordlookup <- coordlookup %>%
rename(locations_edited = locations)
res <- left_join(lookup, coordlookup, by = "locations_edited") %>%
select(-locations_edited)To join the data back together we now need to do two things. First we filter the results from the original search to those that are status == "OK" and then bind the res table to the end.
results_complete <- results %>%
filter(., status == "OK") %>%
bind_rows(., res)We will write the results to an Excel and csv file that we can use in other programmes such as Tableau for mapping (we will briefly look at mapping with R below).
writexl::write_xlsx(results_complete, path = "asean_geocode_complete.xlsx")
write_csv(results_complete, path = "asean_geocode_complete.csv")We now have a complete set of geocoded results with 5,198 locations from 5,206. That is pretty good. However, having obtained the geocoded data and joined it onto our original data.frame we now need to look at the quality of the return.
Assessing the Quality of Geocoding
So far we have focused on getting geocoded data without really looking at it. To assess the quality of the data that has been returned we should take a look at the location type field. The API documentation for these entries can be found here and in the geocode_url() documentation.
results_complete %>%
drop_na(location_type) %>%
count(location_type, sort = TRUE) %>%
mutate(prop = prop.table(n))## # A tibble: 3 x 3
## location_type n prop
## <chr> <int> <dbl>
## 1 ROOFTOP 2155 0.415
## 2 GEOMETRIC_CENTER 1848 0.356
## 3 APPROXIMATE 1195 0.230The API documentation fills us in on what is going on here.
"location_type stores additional data about the specified location. The following values are currently supported:
“ROOFTOP” indicates that the returned result is a precise geocode for which we have location information accurate down to street address precision.
“RANGE_INTERPOLATED” indicates that the returned result reflects an approximation (usually on a road) interpolated between two precise points (such as intersections). Interpolated results are generally returned when rooftop geocodes are unavailable for a street address.
“GEOMETRIC_CENTER” indicates that the returned result is the geometric center of a result such as a polyline (for example, a street) or polygon (region).
“APPROXIMATE” indicates that the returned result is approximate."
What this tells us is that Google believes it has reached rooftop accuracy for 2155 records but has selected the geometric centre or an approximate value for around 58% of the entries. Lets take a closer look at the geometric center data.
results_complete %>%
filter(location_type == "GEOMETRIC_CENTER") %>%
select(locations, lat, lng, formatted_address)## # A tibble: 1,848 x 4
## locations lat lng formatted_address
## <chr> <dbl> <dbl> <chr>
## 1 AAHRI, Bangkok, Thailand 13.8 101. 50, กรมประมง, ถน…
## 2 Aarhus Univ Hosp, Aarhus, Denmark 56.2 10.2 Nørrebrogade, 80…
## 3 Abasyn Univ, Peshawar, Pakistan 34.0 71.6 Ring Road, Chars…
## 4 Abdul Wali Khan Univ, Mardan, Pakistan 34.2 72.0 Nowshera Mardan …
## 5 Abertay Univ, Dundee DD1 1HG, Scotland 56.5 -2.97 Bell St, Dundee …
## 6 Aberystwyth Univ, Ceredigion, Wales 52.4 -4.07 Penglais Campus,…
## 7 Aberystwyth Univ, Dyfed, Wales 52.4 -4.07 Penglais Campus,…
## 8 ABRII, Karaj, Iran 35.8 51.0 Karaj, Alborz Pr…
## 9 Absyn Univ Peshawar, Peshawar, Pakistan 34.0 71.6 Ring Road, Chars…
## 10 Acad Ciencias Cuba, C Habana, Cuba 23.1 -82.4 Havana, Cuba
## # ... with 1,838 more rowsA review of these results suggests that the geometric center data is pretty good. In the past we might have ended up in a different country. But what about the approximate results?
results_complete %>%
filter(location_type == "APPROXIMATE") %>%
select(locations, lat, lng, formatted_address)## # A tibble: 1,195 x 4
## locations lat lng formatted_address
## <chr> <dbl> <dbl> <chr>
## 1 Acad Sci Czech Republic, Brno, … 49.2 16.6 Brno, Czechia
## 2 Acad Sci Czech Republic, Ceske … 49.0 14.5 Ceske Budejovice, Czec…
## 3 Acad Sinica, Beijing, Peoples R… 39.9 116. Beijing, China
## 4 Achva Acad Coll, Mobile Post Sh… 31.7 34.6 Shikmim, Ashkelon, Isr…
## 5 ADAS UK Ltd, Cambs, England 52.2 0.122 Cambridgeshire, UK
## 6 Adv Choice Econ Pty Ltd, Batema… -25.3 134. Australia
## 7 AFRIMS Entomol Lab, Kamphaeng P… 16.5 99.5 Kamphaeng Phet, Thaila…
## 8 Agcy Consultat & Res Oceanog, L… 45.2 1.97 19320 La Roche-Canilla…
## 9 Agcy Marine & Fisheries Res Ind… -6.18 107. Jakarta, Indonesia
## 10 Agcy Marine & Fisheries Res, Ja… -6.18 107. Jakarta, Indonesia
## # ... with 1,185 more rowsThe approximate results are a mixed bag, in some cases the coordinates focus on a city or town. In other cases such as Adv Choice Econ Pty Ltd, Bateman, Australia the coordinate is for a country and so on.
Preprocess the Data and Rerun the Query
This suggests to me at least that while the geocoding is OK the prevalence of geometric centre and approximate results suggests that we might want to run this again but this time edit the location names first to see if we can improve the accuracy of the results. We now know that we can geocode pretty much all of this data. What we are interested in now is whether we can improve the accuracy of the geocoding.
# import data and separate out the organisation country and city into new columns
affiliation2 <- read_csv("https://github.com/wipo-analytics/data-handbook/raw/master/affiliation_records.csv") %>%
separate(locations, c("organisation", "city", "country"), sep = ",", remove = FALSE)
# import abbreviations
wos_abbreviations <- read_csv("https://github.com/wipo-analytics/data-handbook/raw/master/wos_abbreviations.csv",
col_types = cols(abbreviation = col_character(),
text = col_character()))
# function to replace the abbreviations
replaceabbr <- function(pattern, replacement, var) {
replacement <- rep(replacement, length(pattern))
for (i in seq_along(pattern)) {
var <- gsub(pattern[i], replacement[i], var)
}
var
}
# regularise organisation names
affiliation2 <- affiliation2 %>%
mutate(organisation_edited = str_to_title(.$organisation)) %>%
mutate(city = str_to_title(.$city)) %>% # added
mutate(country = str_to_title(.$country)) #added
# fix abbreviations
affiliation2$organisation_edited <-
replaceabbr(wos_abbreviations$regex, wos_abbreviations$text, affiliation2$organisation_edited)
# unite cleaned up fields
affiliation2 <- affiliation2 %>%
unite(., locations_edited, c(organisation_edited, city, country), sep = ",", remove = FALSE)
# run the search
run1 <- placement::geocode_url(affiliation2$locations_edited, auth = "standard_api", privkey = key, clean = TRUE, add_date = 'today', verbose = TRUE)
# drop the input-url and rename for join
run1 <- run1 %>%
select(-8) %>%
rename(locations_edited = locations)
# join to the input table
res_complete <- left_join(affiliation2, run1, by = "locations_edited")
res_complete <- res_complete %>%
mutate(duplicate_id = duplicated(id)) %>%
filter(duplicate_id == "FALSE")When we join the two tables together we discover that we arrive at 5232 rather than 5,206 results. The reason for this is that the name harmonisation has created duplicated names from formerly distinct names. The Google API returns duplicate entries in these cases. These duplicate entries have been filtered out above. We will come on to other forms of duplication below.
Ok let’s take a look at our results to assess whether this is an improvement.
run1 %>%
drop_na(location_type) %>%
count(location_type, sort = TRUE) %>%
mutate(prop = prop.table(n))## # A tibble: 3 x 3
## location_type n prop
## <chr> <int> <dbl>
## 1 ROOFTOP 2280 0.439
## 2 GEOMETRIC_CENTER 1927 0.371
## 3 APPROXIMATE 981 0.189What this has done is improved the rooftop resolution by a couple of percentage points and improved the geometric centre results by about the same. The approximate score has dropped to 19% from 23% so this is definitely progress. In total 214 records have moved up from the approximate to the rooftop or geometric centre location_types. As this suggests, improving the quality of geocoding matters and it is therefore worth putting the effort into improving the resolution of the results.
Duplicated Affiliation Names
It will not have escaped your attention that in reality our original input data contained a significant amount of duplication on organisation names. This becomes obvious when we review the organisation edited field. We can rapidly see multiple entries.
affiliation2 %>%
count(organisation_edited, sort = TRUE)## # A tibble: 4,042 x 2
## organisation_edited n
## <chr> <int>
## 1 University Putra Malaysia 19
## 2 Chinese Academy Science 15
## 3 Mahidol University 15
## 4 Prince Songkla University 14
## 5 University Philippines 14
## 6 Cnrs 12
## 7 Department Fisheries 12
## 8 Fisheries Research Agency 12
## 9 Indonesian Institute Science 12
## 10 Ministry Health 12
## # ... with 4,032 more rowsThere are a number of reasons for this. In some cases researchers may list different departments or institutes along with the name of their organisation. In other cases an organisation (such as the Chinese Academy of Science or CNRS) may have multiple offices within or outside a particular country. In still other cases, such as Department Fisheries or Ministry Health we are lumping together organisations that share the same name but are distinct entities.
Lets take a closer look at this.
affiliation2 %>%
select(locations, organisation_edited) %>%
head(20)## # A tibble: 20 x 2
## locations organisation_edited
## <chr> <chr>
## 1 AAHL, Vic, Australia Aahl
## 2 AAHRI, Bangkok, Thailand Aahri
## 3 Aarhus Univ Biosci, Roskilde, Denmark Aarhus University Bioscience
## 4 Aarhus Univ Hosp, Aarhus, Denmark Aarhus University Hospital
## 5 Aarhus Univ, Aarhus C, Denmark Aarhus University
## 6 Aarhus Univ, Aarhus, Denmark Aarhus University
## 7 Abasyn Univ, Peshawar, Pakistan Abasyn University
## 8 Abdul Wali Khan Univ, Mardan, Pakistan Abdul Wali Khan University
## 9 Abertay Univ, Dundee DD1 1HG, Scotland Abertay University
## 10 Aberystwyth Univ, Ceredigion, Wales Aberystwyth University
## 11 Aberystwyth Univ, Dyfed, Wales Aberystwyth University
## 12 Abo Akad Univ, Turku, Finland Abo Akad University
## 13 ABRII, Karaj, Iran Abrii
## 14 Absyn Univ Peshawar, Peshawar, Pakistan Absyn University Peshawar
## 15 Acad Ciencias Cuba, C Habana, Cuba Academy Ciencias Cuba
## 16 Acad Nat Sci Philadelphia, Philadelphia,… Academy Natural Science Phil…
## 17 Acad Sci Czech Republ, Ceske Budejovice,… Academy Science Czech Republ
## 18 Acad Sci Czech Republic, Brno, Czech Rep… Academy Science Czech Republ…
## 19 Acad Sci Czech Republic, Ceske Budejovic… Academy Science Czech Republ…
## 20 Acad Sci Czech Republic, Prague, Czech R… Academy Science Czech Republ…In the case of Aarhus University, we can see that we have Aarhus University Bioscience, Aarhus University Hospital and an Aarhus University. In some cases the entities belong to the organisation but might otherwise be regarded as distinct (Aarhus University Hospital) while in another the Bioscience reference refers to a department (but gives the impression that it may be a separate University as for Agricultural cases). To add to this we note that there are locations in Aarhus and Roskilde and a minor variant (Aarhus C) in the address field.
As this makes clear address field data in scientific names is pretty messy because authors choose how to denote their affiliations, and are perhaps rebelling against the tyranny of performance indicators and endless research assessment exercises.
Cleaning up author affiliation and author names is generally a painful process (and we will come back to this in a future article). One challenge with name cleaning is the availability of criteria to determine if a name can be merged. For example, we could comfortably merge some of the Aarhus University references above but we might want to keep distinct locations distinct (for example Aarhus is around 150km by road from Roskilde). The availability of georeferenced data, bearing in mind the approximates issue, could provide us with additional information for informed decision making during name cleaning. Let’s take a quick look at the formatted address field in our results.
res_complete %>%
select(formatted_address, organisation_edited) %>%
head(20)## # A tibble: 20 x 2
## formatted_address organisation_edited
## <chr> <chr>
## 1 5 Portarlington Road, Newcomb VIC 3219, Austral… Aahl
## 2 50, กรมประมง, ถนนพหลโยธิน, ลาดยาว จตุจักร Bangk… Aahri
## 3 Aarhus University, 150, Frederiksborgvej 399, 4… Aarhus University Bio…
## 4 Nørrebrogade, 8000 Aarhus, Denmark Aarhus University Hos…
## 5 Langelandsgade 140, 8000 Aarhus, Denmark Aarhus University
## 6 Langelandsgade 140, 8000 Aarhus, Denmark Aarhus University
## 7 Ring Road, Charsadda Link، Near Patang Chowk، A… Abasyn University
## 8 Nowshera Mardan Rd, Muslimabad, Mardan, Khyber … Abdul Wali Khan Unive…
## 9 Bell St, Dundee DD1 1HG, UK Abertay University
## 10 Penglais Campus, Penglais, Aberystwyth SY23 3FL… Aberystwyth University
## 11 Penglais Campus, Penglais, Aberystwyth SY23 3FL… Aberystwyth University
## 12 Domkyrkotorget 3, 20500 Åbo, Finland Abo Akad University
## 13 Karaj, Alborz Province, Iran Abrii
## 14 Ring Road, Charsadda Link، Near Patang Chowk، A… Absyn University Pesh…
## 15 Havana, Cuba Academy Ciencias Cuba
## 16 1900 Benjamin Franklin Pkwy, Philadelphia, PA 1… Academy Natural Scien…
## 17 Branišovská 1645/31A, České Budějovice 2, 370 0… Academy Science Czech…
## 18 Palackého tř. 1946/1, 612 42 Brno-Královo Pole,… Academy Science Czech…
## 19 Branišovská 1645/31A, České Budějovice 2, 370 0… Academy Science Czech…
## 20 Žitná 609/25, 110 00 Praha-Nové Město, Czechia Academy Science Czech…Here we can see that the Google data suggests that some of these entities share an address. Based on this we may want (with appropriate attention to the location type field as a guide) to merge or not merge names in our list. If we take a look at the counts for shared addresses it becomes clear that we may want to use a step wise approach depending on the level of confidence in the location type field.
res_complete %>%
filter(location_type == "ROOFTOP") %>%
count(formatted_address, sort = TRUE)## # A tibble: 1,653 x 2
## formatted_address n
## <chr> <int>
## 1 113 Soi Klong Luang 17, Tambon Khlong Nung, Amphoe Khlong Luang,… 16
## 2 18 Hoàng Quốc Việt, Nghĩa Đô, Cầu Giấy, Hà Nội, Vietnam 14
## 3 169 Long Had Bangsaen Rd, Tambon Saen Suk, อำเภอ เมืองชลบุรี Cha… 11
## 4 15 Karnjanavanit Soi 7 Rd, Kho Hong, Amphoe Hat Yai, Chang Wat S… 9
## 5 999 Phutthamonthon Sai 4 Rd, Tambon Salaya, Amphoe Phutthamontho… 9
## 6 Jl. Pasir Putih Raya No.1, RT.8/RW.10, Kota Tua, Pademangan Tim.… 9
## 7 New Administration Building, Miagao, 5023 Iloilo, Philippines 9
## 8 02 Nguyễn Đình Chiểu, Vĩnh Thọ, Thành phố Nha Trang, Vĩnh Thọ Th… 8
## 9 Nørregade 10, 1165 København, Denmark 8
## 10 Pesthuislaan 7, 2333 BA Leiden, Netherlands 8
## # ... with 1,643 more rowsQuickly Mapping the Data
To finish off lets quickly map the data. We will focus on mapping in more detail in other articles in the Handbook. For the moment we will use the leaflet package for this.
install.packages("leaflet")library(leaflet)
mapdata <- res_complete %>%
filter(., status == "OK")
mapdata <- leaflet(mapdata) %>%
addTiles() %>%
addCircleMarkers(~lng, ~lat, popup = .$locations_edited, radius = mapdata$records / 20, weight = 0.1, opacity = 0.2, fill= TRUE, fillOpacity = 0.2)
mapdataAs this makes clear it is relatively straightforward to generate quick maps with R and even easier to export the data to tools such as Tableau for publication quality and interactive maps. We will go into mapping in more depth in a future article.
Round Up
In this article we looked at three R packages for geocoding data on research affiliations from the scientific literature using Web of Science. We focused on the use of the placement package as it is very easy to use. However, your needs may differ with packages such as ggmap and googleway offering different functionality.
The main take away message is that geocoding using the Google Maps API will normally be an iterative process that may requires multiple passes and adjustments to the data to arrive at accurate results. One things should now also be clear, while the Google Maps API has dramatically improved in its ability to offer geocoded results (including on messy names) these results should not be taken at face value. Instead, and depending on your purpose, multiple iterations may be needed to improve the resolution of the results. In this article we have not gone all the way with this but have hopefully provided enough pointers to allow you to take it further.
R is a functional programming language meaning that it will be feasible to construct a function that brings together the functions used to process the data in the above steps. We will not go there today, but to round up lets think about some of the elements that we might want to use to address this in a single R function based on the steps that we have taken above.
- import dataset
- address case issues
- separate organisation, city, country
- resolve abbreviations on organisation names
- unite organisation, city and country into a new field
- send the cleaned field to the API and retrieve results
- adjust column names to match
- join results to original
- review the location type
- adjust and rerun as needed to improve rooftop and geometric centre results vs. approximate results
In many cases it will make sense to choose a threshold based on counts of records before sending the data to the API. For example where dealing with publications (as in this case) it could make sense to exclude records where there is only one record. For example, in our original input table 1,624 entries only had one record. If no one is ever likely to look at data points with only one record you may wish to filter them out and concentrate on the accuracy of geocoding for scores above the threshold.
We have also seen that while the focus of geocoding is logically on mapping, in reality geocoding services may offer new opportunities for the vexed problem of accurate name cleaning when working with the scientific literature or patent data. We will look at this in more detail in a future article. For the moment, congratulations, you have survived geocoding using the Google Maps API in R.
References
Wickham, Hadley. 2017. Tidyverse: Easily Install and Load the ’Tidyverse’. https://CRAN.R-project.org/package=tidyverse.
———. 2018. Stringr: Simple, Consistent Wrappers for Common String Operations. https://CRAN.R-project.org/package=stringr.
Wickham, Hadley, and Jennifer Bryan. 2018. Usethis: Automate Package and Project Setup. https://CRAN.R-project.org/package=usethis.
Wickham, Hadley, Romain François, Lionel Henry, and Kirill Müller. 2018. Dplyr: A Grammar of Data Manipulation. https://CRAN.R-project.org/package=dplyr.
Wickham, Hadley, and Lionel Henry. 2018. Tidyr: Easily Tidy Data with ’Spread()’ and ’Gather()’ Functions. https://CRAN.R-project.org/package=tidyr.